

Applies to AnyLogic Cloud 2.6.1. Last modified on January 14, 2026.
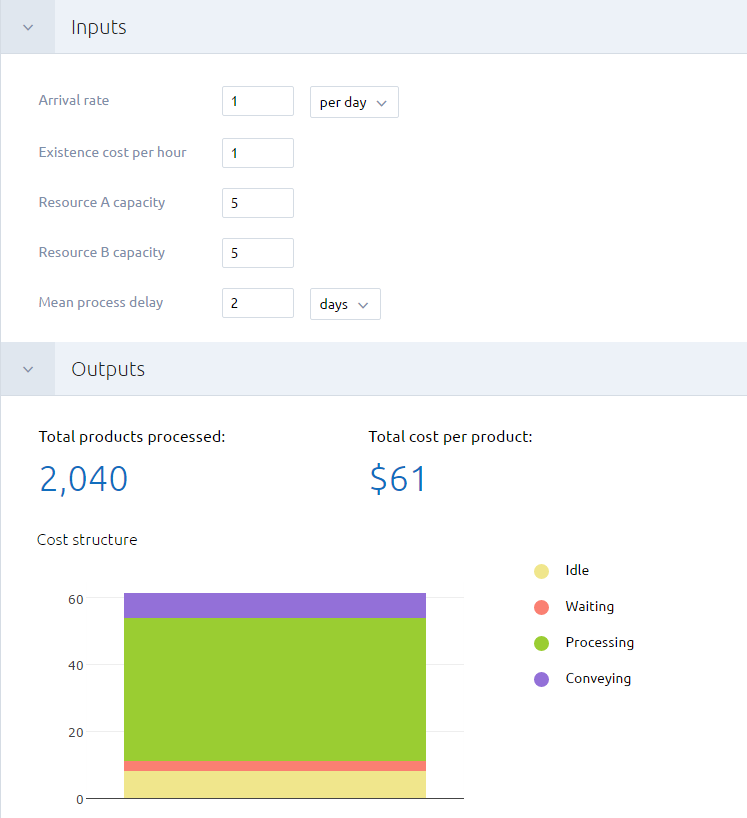
The experiment dashboard displays the current state of the experiment:
- The Inputs section lists the modifiable parameters of the exposed model version.
- The Outputs section lists the outputs of the model version if the experiment has already been run. The section is blurred if the experiment has not yet been run.
The values on the dashboard correspond to the experiment template: a “blueprint” of a Cloud experiment. The template describes the run configuration for the AnyLogic Cloud experiment in the JSON format. This includes the model version, inputs, outputs, output widgets, and input widgets. When you upload a new version of a model, the system automatically creates a new experiment using this template. It also checks for any changes in the inputs and outputs, and updates the user interface accordingly.
The first time you upload a model to AnyLogic Cloud or create it in the web editor, a simulation experiment is created that fully matches the experiment template of the uploaded model version. When subsequent versions of the model are uploaded, a migration utility checks which input and output widgets of the experiment in the existing version are present in the new experiment template and transfers them to the corresponding experiments of the new version. This utility also checks for any new input and output widgets and adds them to the dashboards.
In Cloud versions prior to 2.5.0, when creating a new version, the default value of an input in the experiment was not checked. Input values in the experiment always carried over from the previous version, regardless of any changes to the default values in the model itself. As a result, AnyLogic Cloud never automatically updated the default values of the inputs in the experiment.
Starting with version 2.5.0, a new default value is applied to inputs with a default value at the time the new version is created. This ensures that the inputs used in the experiment are up to date with the latest model version. The default value is either taken directly from the default value of the parameter in AnyLogic or evaluated before exporting to Cloud if it is defined in code. The new default value is applied to the inputs with the default value at the time of export, and the value from the previous experiment is used for inputs with a non-default value.
Consider the following arrangement of the values:
|
Previous version Value in AnyLogic before exporting to Cloud |
Previous version Value in Cloud adjusted in the Cloud UI |
New version Value in AnyLogic before exporting to Cloud |
Resulting value On the dashboard |
|
|---|---|---|---|---|
| Input 1 | 1 | 1 | 2 | 2 |
| Input 2 | 2 | 3 | 4 | 3 |
The behavior is slightly different for selection-based controls that have default values, such as drop-down boxes and radio buttons. Before updating, Cloud verifies that the new version includes values that match to the old version by comparing names and values. For example, if the old experiment uses a default value, Cloud sets the updated name and its corresponding default value. If the old experiment uses a non-default value, Cloud checks if it exists in the new template by matching the index. If the value is found, its new name is applied. If the value is not found, it is set to the default value of the new experiment. If there are duplicate names, they are listed in the order of occurrence.
In addition, version 2.5.3 fixes an issue where the inputs (depending on their visibility settings) could behave inconsistently during conversion between the model editor and AnyLogic Cloud. Now, hidden inputs will remain hidden after uploading a new version from the editor, as long as the input exists in the new version. The migration of both values and widgets works the same way for both visible and hidden inputs; the only difference being that hidden inputs are not displayed on the dashboard.
To change the value of an input, use the control next to the input. You can do the following:
- Type a new value in the edit box,
- Select a new value from the combo box,
- Switch between radio buttons, and so on.
If your experiment uses files as inputs, you can also replace the files using the appropriate controls.
After entering new values, click ![]() to save the new input values in the experiment. The new values will become default for the experiment.
to save the new input values in the experiment. The new values will become default for the experiment.
If you accidentally hide necessary outputs, you can simply specify the identical input values, and AnyLogic Cloud will retrieve them from the database and display them in the Outputs section.
Some inputs in multi-run experiments (that is, all experiments in AnyLogic Cloud except Simulation) can be discrete ranges. You’ll need to define the lower and upper limits of the range, as well as the step. AnyLogic Cloud will assign values from this range using the specified step between runs. The range for Boolean inputs is always {true, false}.
In optimization experiments (Optimization and Optimization with replications), one or more inputs can be continuous ranges. They work similarly to the discrete range inputs, but their values are determined by the optimization engine.
If the input values that you have provided differ from the experiment’s defaults, you can discard the changes to return the input values to their default state.
To discard changes to the experiment’s input values
- Click the
 Discard changes button. The input values are returned to their default state.
Discard changes button. The input values are returned to their default state.
To download the results saved in the output file
- On the right of the Outputs section of the experiment screen, locate the link to the desired output file.
- Click the link.
The download is handled by the browser. Depending on your browser settings, you may be able to specify the download location or rename the file if necessary.
To set up values for date inputs (such as Start date, Stop date, or custom Date type inputs), you can use the graphical date and time picker, which can be opened by clicking . After selecting the date, click Save in the picker to apply the changes.
To enter the date manually, use the following format:
yyyy-MM-dd hh:mm:ss
- The year must be a four-digit value between 1600 and 9999.
- The month, day, hour, minutes, and seconds must be two-digit values.
- If you set up the start date and stop dates manually, make sure that the stop date is later than the start date.
- The stop time (if set separately) must also be later than the start time.
When creating an optimization experiment (Optimization or Optimization with replications), you should set its Objective. The objective is a numerical value (int or double) that you want to minimize or maximize through the optimization experiment.
The Objective control is already available in the Inputs section when you create an experiment. You must select one of the experiment’s outputs from the drop-down list and specify whether you want to minimize or maximize it using the Minimize and Maximize radio buttons.
In addition, AnyLogic Cloud optimization experiments support requirements. A requirement is an additional restriction placed on the solution found by the optimization engine. These requirements are checked after each simulation run, and if they are not met, the used inputs are rejected. Otherwise, they are accepted.
By default, the requirements are hidden, but you can make them visible in the dashboard editor.
To configure a requirement
- Go to the dashboard editor.
- Locate the Requirements section below the experiment settings.
-
The Requirements section lists all the numeric (int and double) inputs of the model.
To create a requirement for a particular input, make it visible by clicking . - Save the dashboard.
- The Requirements block will appear in the Inputs section, displaying the name of the input you have selected, a drop-down list, and an edit box.
-
In the drop-down list, select the type of restriction you want to apply to the input:
- Not restricted
- Greater than or equal to
- Less than or equal to
- In range
- In the edit box, specify the value (or range) that will serve as the limit for the corresponding input.
Now, when the optimization process is complete, if the requirement is not satisfied during the simulation run, the optimization engine will consider the solution for that run infeasible, and the objective will remain unfulfilled.
You can configure the contents of the experiment dashboard by including the desired set of inputs and outputs and organizing them into sections.
To edit the dashboard contents
-
In the sidebar of the experiment screen, expand the model version that contains the experiment you want to configure.
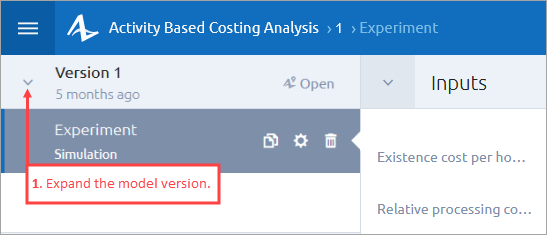
-
Click the required experiment, then click the icon that appears to the right. The cog icon changes to
 .
.
The experiment dashboard will switch to edit mode, allowing you to modify its contents: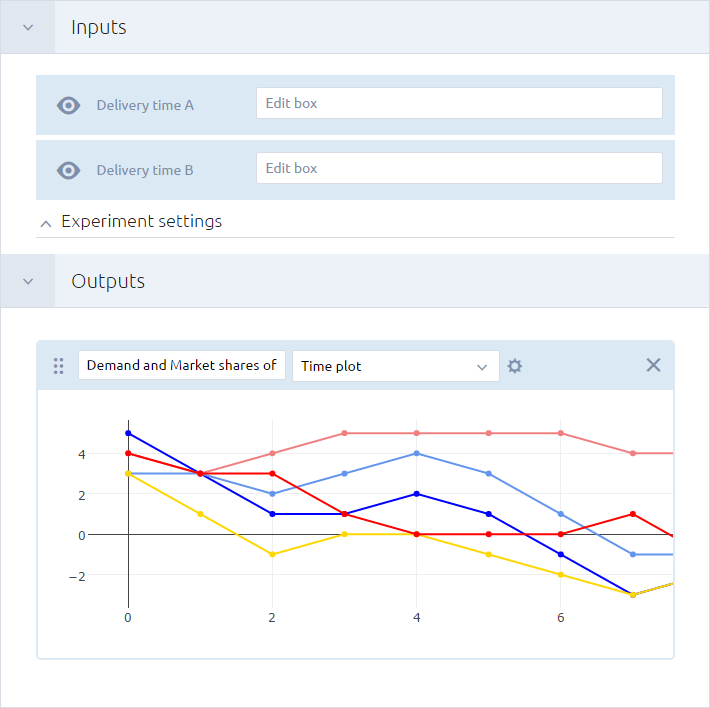
- Configure the Inputs and Outputs sections as needed.
- If you want to change the experiment’s name, type the new name in the edit box in the sidebar.
- Save your changes by clicking the Save dashboard button in the experiment toolbar or the
 button in the sidebar. To discard changes, click the Cancel button in the experiment toolbar.
button in the sidebar. To discard changes, click the Cancel button in the experiment toolbar.
When configuring the Inputs section, you can toggle the visibility of the experiment’s inputs, change the control types of the inputs, and expose the experiment’s internal settings:
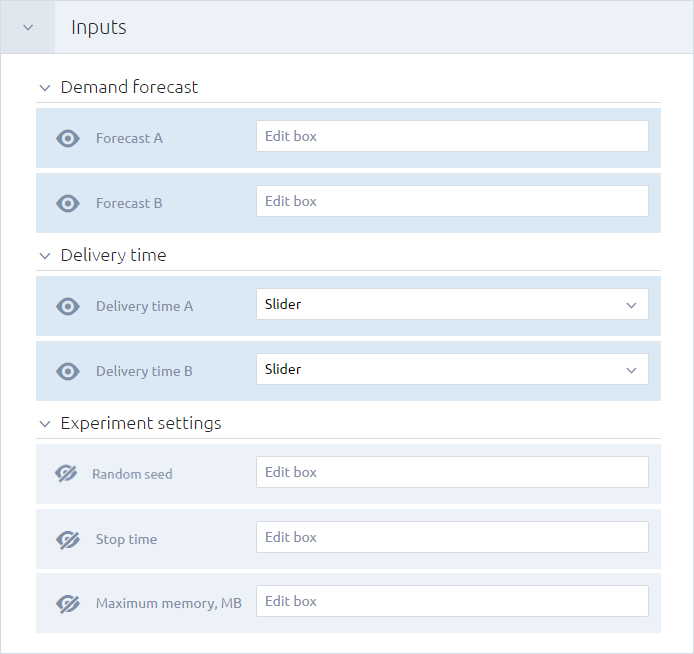
To show or hide an input element
- Click the icon to the left of the element. The element will be hidden and the icon will change to . Click the icon again to make the element visible.
Multi-run experiments imply that you may want to vary some inputs. Currently, you can make int, double, and Boolean inputs vary in range.
To vary an input, simply select Discrete range from the drop-down list next to the input’s name in the AnyLogic Cloud dashboard editor.
In optimization experiments, you can also make double inputs continuous ranges by selecting the appropriate option from the input’s drop-down list. When this option is selected for an input, the optimization engine generates the values for that input.
The order in the Inputs section mirrors that of the top-level agent of the model (usually the Main agent).
To set the order of the parameters in the Inputs section of the model experiment, you need to change the options in the Parameters preview section of the main agent properties in AnyLogic.
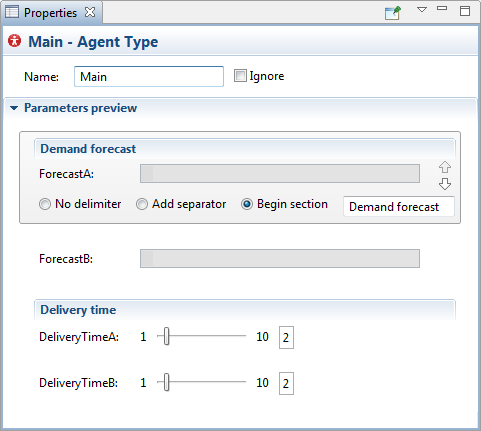
You can adjust each parameter as follows:
- Use the
 and
and  arrows to move a parameter up or down in the list.
arrows to move a parameter up or down in the list. - To add a separating line above the parameter, select the Add separator option.
- To start a new section beginning with the parameter, select the Begin section option and enter the section name in the text field.
Model input names and associated control types are defined in the Value editor section of the corresponding parameter’s properties before exporting the model:
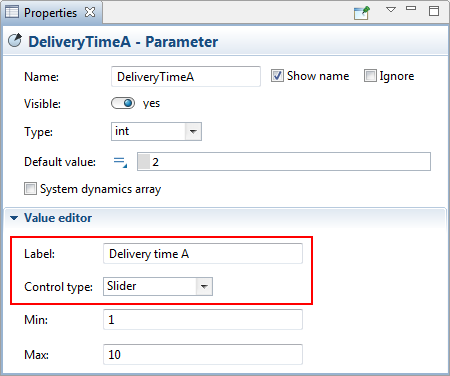
The Experiment settings section contains the internal settings of the experiment.
The following default control types are hidden by default, but you can make them available in the experiment’s dashboard if desired.
- Random seed — The number used to initialize the model’s random number generator.
-
Stop at — Defines the trigger that will stop the simulation. To define the simulation period, use the Start time, Start date, Stop time, and Stop date controls.
The defined start/stop time/date values can override the default values that you specified when exporting the model to AnyLogic Cloud.
- Start time — The time point at which the experiment will begin.
- Start date — The date when the experiment will begin.
- Stop time — The time point at which the experiment will stop.
- Stop date — The date when the experiment will stop.
- Maximum memory, MB — The maximum size of the Java heap allocated for the model. Here you can override the default value that you specified when setting up the model for AnyLogic Cloud.
If your model’s run configuration contains files that serve as inputs, from there you can also override the uploaded file using the corresponding control.
Some experiments have unique control types that are visible in the Inputs section by default. These are relevant for the models that contain stochastics. For these experiments, the results of the simulation runs are unique and the values obtained for simulation runs performed with the same values are likely to be different. This means that the results obtained during a single simulation run may be unreliable, so we need to perform multiple runs (called replications or iterations, depending on the type of stochastic input set) for a single set of inputs.
-
Monte Carlo 1st order:
- Number of replications — How many replications will be performed, that is, how many different random seeds will be used to run the experiment.
-
Monte Carlo 2nd order:
- Number of iterations — How many times the different sets of inputs will be used to run the experiment. Depending on the type of experiment, the inputs are either random or generated by the optimization engine.
- Number of replications — How many replications will be performed, that is, how many different random seeds will be used to run the experiment.
-
Variation with replications:
- Number of replications — How many replications will be performed, that is, how many different random seeds will be used to run the experiment.
-
Optimization:
- Objective — The objective of the optimization experiment (see above).
- Number of iterations — How many times the different sets of inputs will be used to run the experiment. Depending on the type of experiment, the inputs are either random or generated by the optimization engine.
-
Optimization with replications:
- Objective — The objective of the optimization experiment (see above).
- Number of iterations — How many times the different sets of inputs will be used to run the experiment. Depending on the type of experiment, the inputs are either random or generated by the optimization engine.
-
Number of replications — How many replications will be performed, that is, how many different random seeds will be used to run the experiment.
Due to the algorithm used by the genetic optimization engine, the actual number of iterations may differ from the value you specify, but it will always be a multiple of 32.
When configuring the Outputs section, you can add or remove the output data elements and freely position them within the Outputs area.
You can add the following elements:
- Outputs — charts and text labels that display the values of the model’s outputs.
- Collapsible sections which group the dashboard elements.
- Separating lines which divide the workspace into distinct areas.
To add an element, click the  button. To remove an element, click the
button. To remove an element, click the  icon in its upper right corner.
icon in its upper right corner.
For more information about the different types of output and charts available in Cloud, see the appropriate section: Experiment charts.
To add a section
-
Click in the Add section placeholder. A section heading is created:

-
Type the section name in the text box:

-
The section is initially empty. Add outputs to the section by dragging them under the section header:
Alternatively, you can drag the section header itself using the
 drag handle on its left edge. Position the section above the outputs you want to include in it.
drag handle on its left edge. Position the section above the outputs you want to include in it.
To visually divide the workspace into distinct areas, you can add a horizontal line between the output elements.
To add a separating line
- Click the
 button. The separating line will appear in the workspace.
button. The separating line will appear in the workspace. - Position the line as needed by dragging it with the handle on its left edge.
-
How can we improve this article?
-