

Пользователи AnyLogic могут не только использовать любое из поддерживаемых распределений вероятности, но и задать эмпирические (нестандартные) распределения вероятности, основываясь на имеющейся выборке (выборочной совокупности).
Получать случайные значения согласно заданному в модели эмпирическому распределению можно, вызвав функцию с тем же именем, что и это распределение, например: myDistribution().
Чтобы задать эмпирическое распределение
-
Перетащите элемент
 Эмпирическое распределение из палитры Агент на графическую диаграмму агента.
Эмпирическое распределение из палитры Агент на графическую диаграмму агента.
- Перейдите в свойства элемента, чтобы ввести данные и таким образом построить распределение.
- Сначала выберите Тип распределения из доступных: Непрерывное или Дискретное. Дискретное распределение будет возвращать только одно из заданных вами значений. Непрерывное - любые значения из заданных вами интервалов.
- Задайте данные эмпирического распределения в секции Данные одним из способов:
Чтобы загрузить данные из существующей базы данных Anylogic, выберите опцию Загружается из базы данных и выберите таблицу БД из раскрывающегося списка Таблица. Если необходимо, укажите в пункте свойств Условия выборки условия, определяющие значения, которые будут выбраны из указанного столбца таблицы. В расположенных ниже свойствах задайте столбцы таблицы БД, содержащие требуемые данные (в соответствии с типом распределения, см. ниже).
Если данные уже заданы в другом файле или приложении, то вы можете скопировать их в буфер обмена, после чего вставить их в таблицу секции Данные, нажав на кнопкуВставить из буфера. Предварительно необходимо снять флажок с опции Загружается из базы данных.
Табличные данные можно также ввести вручную в таблицу (которая доступна в секции свойств Данные, если не выбрана опция Загружается из базы данных). Чтобы удалить запись из таблицы, выберите соответствующий ряд таблицы и нажмите на кнопкуУдалить. Используйте кнопки
и
, чтобы изменить порядок данных в таблице (эти кнопки доступны, если в опции Режим задания выбран вариант Частотная таблица или Набор наблюдений). Данные для различных типов эмпирического распределения задаются различными способами. Мы описали эти способы в следующих разделах:
- Общие свойства
-
Имя — Имя эмпирического распределения. Имя используется для идентификации распределения. Вы можете вызывать распределение как функцию, например: myDistribution().
Отображать имя — Если опция выбрана, то имя распределения будет отображаться в графическом редакторе.
Исключить — Если опция выбрана, то распределение будет исключено из модели.
Видимость — Здесь вы можете указать, будет ли распределение видно на анимации во время выполнения модели. Используя элемент управления, выберите да или нет.
Тип — Тип распределения:
Непрерывное — Распределение задается данными непрерывного типа.
Дискретное — Распределение задается данными дискретного типа.
Режим задания — Укажите, каким образом будет задаваться распределение:
Частотная таблица — Распределение задается с помощью частотной таблицы.
Возвращает целые числа — [Параметр виден, если для параметра Тип выбрана опция Непрерывное] Если опция выбрана, то распределение будет возвращать только целочисленные значения. Список вариантов — [Параметр виден, если для параметра Тип выбрана опция Значение] Здесь вы можете выбрать список вариантов для эмпирического распределения. Распределение будет задавать вероятности для каждой опции данного списка.
Набор наблюдений — Вы загружаете наблюдаемые значения, как они есть. Частотность каждого конкретного значения зависит от того, сколько раз данное значение встречается в таблице (т.е. сколько раз данное значение наблюдалось). Используйте этот способ, если у вас есть данные наблюдений.
Интервалы — [Опция доступна, если в параметре Тип выбрана опция Непрерывное] Распределение задается с помощью интервалов.
Список вариантов — [Опция доступна, если для параметра Тип выбрана опция Дискретное] Позволяет задавать вероятности для каждой альтернативной опции выбранного списка вариантов. - Данные
-
Здесь вы можете задать данные для эмпирического распределения. Данные могут задаваться в таблице (см. инструкции ниже) или загружаться из базы данных AnyLogic.
Загружается из базы данных — Если выбрана эта опция, данные можно загружать из существующей базы данных AnyLogic, заданной пользователем.
Таблица — Здесь вы можете выбрать таблицу с необходимыми данными из базы данных AnyLogic.
Условия выборки — Здесь вы можете задать одно или несколько условий, с помощью которых из заданных табличных столбцов будут выбираться конкретные значения. Вы можете добавлять
 , копировать
, копировать  , удалять и менять местами условия (, ).
, удалять и менять местами условия (, ).Столбец значений — [Опция доступна, если для параметра Режим задания выбрана опция Частотная таблица или Набор наблюдений] Столбец таблицы БД, который содержит значения.
Столбец весов — [Опция недоступна, если для параметра Режим задания выбрана опция Набор наблюдений] Вероятности для соответствующих значений в Столбце значений.
Начальный столбец — [Опция доступна, если для параметра Режим задания выбрана опция Интервалы] Столбец таблицы БД, содержащий значения, с которых начинаются интервалы данных.
Конечный столбец — [Опция доступна, если для параметра Режим задания выбрана опция Интервалы] Столбец таблицы БД, содержащий значения, которыми завершаются интервалы данных.
Столбец с вариантами — [Опция доступна, если для параметра Тип выбрана опция Список вариантов] Столбец таблицы БД, содержащий варианты Списка вариантов. Типом данного столбца должен быть тот же список вариантов, который вы задали в параметре Список вариантов этого эмпирического распределения.
- Предв. просмотр
-
Здесь отображается предварительный просмотр вашего эмпирического распределения - гистограмма, полученная путем генерации 100 000 значений согласно заданному распределению.
- Специфические
-
Эта секция свойств отобраажется только в том случае, если включен Режим разработчика библиотек.
Статический — Если эта опция выбрана, эмпирическое распределение становится статическим. Статическое распределение инициализируется один раз и содержит одни и те же данные для всех экземпляров данного типа агента. Это очень удобно при работе с агентными моделями, если для ваших агентов заданы какие-то распределения. Объявив эмпирическое распределение статическим, мы избегаем потерь времени, которое тратилось бы исполняющим модулем AnyLogic на многократную инициализацию распределения для многих агентов.
Не используйте статическое эмпирическое распределение, если вы собираетесь параллельно выполнять итерации сложных экспериментов (оптимизация, варьирование параметров и т.д.) на разных ядрах процессора (это задается параметром Разрешить параллельное выполнение итераций в разделе свойств эксперимента Специфические).Данные статического эмпирического распределения не сохраняются в файл состояния модели при сохранении / восстановлении состояния выполняемой модели. Если вы не меняете данные статического эмпирического распределения в вашей модели, состояние восстановленной модели будет идентично тому состоянию, которое вы сохранили в файл состояния модели. При этом, если вы как-то изменили данные статического эмпирического распределения (например, в коде При запуске, заданном в свойствах агента), измененные данные не сохранятся в файл состояния модели и состояние восстановленной модели будет отличаться от состояния модели, которое вы сохранили до этого.
Мы опишем два основных способа задания данных для дискретного типа распределения. Выбрать способ можно в параметре Режим задания в панели Свойства эмпирического распределения.
Частотная таблица. Здесь вы задаете значения в первом столбце таблицы и соответствующие веса во втором столбце.
Набор наблюдений. Этот способ позволяет загрузить данные наблюдений, как они есть. Частотность каждого конкретного значения зависит от того, сколько раз данное значение встречается в таблице (т.е. сколько раз данное значение наблюдалось). Используйте этот способ, если у вас есть таблица с данными наблюдений. Проще всего загрузить данные в модель следующим образом: скопируйте их в буфер обмена из исходного файла или программы с данными, а затем вставьте в AnyLogic, нажав на кнопку Вставить из буфера обмена, расположенную под таблицей в секции свойств Данные.
Откройте секцию свойств Предв. просмотр, чтобы увидеть предварительную версию распределения, построенного на основе данных, которые вы загрузили.
 Дискретный тип распределения, где данные заданы с помощью Набора наблюдений.
Дискретный тип распределения, где данные заданы с помощью Набора наблюдений.  Секции Данные и Предв. просмотр.
Секции Данные и Предв. просмотр.
Существует три способа задать данные для непрерывного типа распределения:
Интервалы. Вы задаете интервалы и вероятности (веса) для этих интервалов.
Частотная таблица. Здесь вы задаете значения в первом столбце таблицы и соответствующие веса во втором столбце.
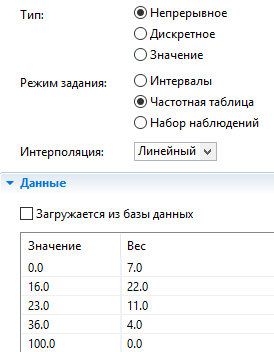 Непрерывный тип распределения, где данные заданы с помощью Частотной таблицы с линейным типом интерполяции.
Непрерывный тип распределения, где данные заданы с помощью Частотной таблицы с линейным типом интерполяции. 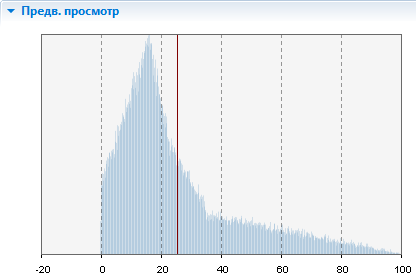 В секции Предв. просмотр вы можете увидеть интервалы со спадом.
В секции Предв. просмотр вы можете увидеть интервалы со спадом.
Набор наблюдений. Этот способ позволяет загрузить данные наблюдений как они есть. Частотность каждого конкретного значения зависит от того, сколько раз данное значение встречается в таблице (т.е. сколько раз данное значение наблюдалось). Вес каждого отдельного значения в таблице равен единице. Используйте этот способ, если у вас есть таблица с данными наблюдений. Проще всего загрузить данные в модель следующим образом: скопируйте их в буфер обмена из исходного файла или программы с данными, а затем вставьте в AnyLogic, нажав на кнопку Вставить из буфера обмена, расположенную под таблицей в секции свойств Данные.
AnyLogic предоставляет возможность программного создания эмпирического распределения с помощью конструктора соответствующего класса: CustomDistributionDiscrete, CustomDistributionContinuous, CustomDistributionOptions.
-
Как мы можем улучшить эту статью?
-